
Users were seeing transient performance slowdowns every day between 15:00 and 16:00. The slowdowns would typically last for 2-3 minutes and occur one or more times during this time window. After looking at things on the SQL Server and database side, it was clear the problem was elsewhere. In fact it was clear that the problem had to do with network congestion, but I needed documentation.
The first thing I did was use the SysInternals PSPing utility and PowerShell to better define the scope of the problem. PSPing has some cool features including the ability to ping over specific TCP ports, a corresponding server mode, and an optional histogram display. I won’t bore you with the details here; go read about it if you’re interested. PowerShell was used to iteratively run PSPing and redirect the output to a file. I also output a timestamp to the file with each iteration. PSPing and PowerShell clearly showed the dimension of the problem as well as the times the problem occurred. The output showed multiple latencies in excess of 3000 mS. The periods of high latency typically lasted between 1 and 10 seceonds.
I also used tracetcp and tracert to further isolate the problem. Both utilities show latency by router hop. High latency values started at the first MPLS router hop.
I needed to figure out what was driving the congestion, so I downloaded and installed a 30-day demo of a NetFlow analyzer. I configured the core router and switches to export NetFlow data to the PC running the Netflow analyzer software. From there it was pretty easy to drill down and find the source of the problem. The image below shows what was happening. SMTP traffic was maxing out a 20Mbit MPLS circuit. After querying a few users, I found what was causing the problem – a daily client mass-mailing. Pretty simple really.
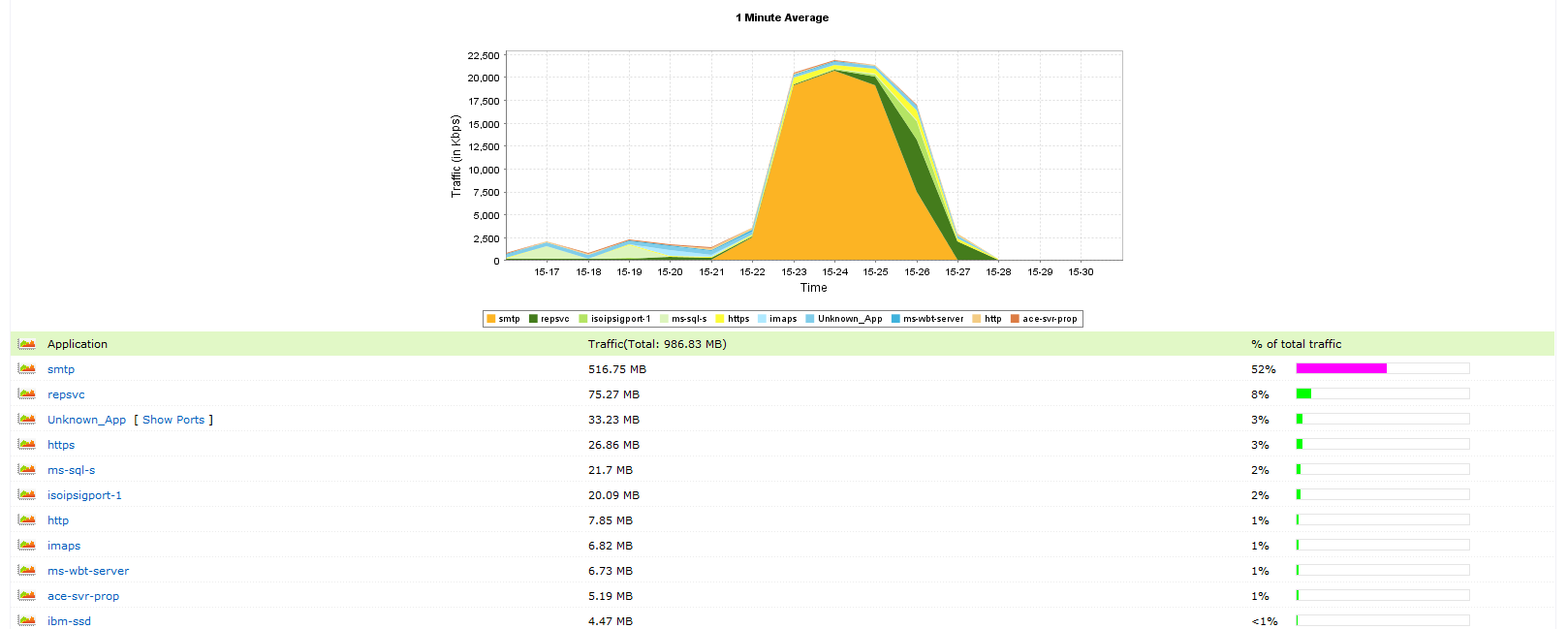
NetFlow capture
{kind=link}